목 차
1. 들어가며
2. 사전설명
1) 1분봉 데이터 받아올 때 특징
2) 데이터 합치기
3. 데이터 받아온 후 주의사항
1) RSI 14 등 계산이 필요한 일부 데이터는 없음
2) 마지막줄 데이터의 종가는 현재가이다.
3) "구분"에 제목은 바꾸어줄 필요가 있다.
4) 중복 데이터 삭제
5) 신규 데이터를 붙이는 경우
4. 마치며
1. 들어가며
지난 글에서는 1분봉 데이터를 파이썬의 concat 내장함수를 통해 한 파일(엑셀)로 합치는 방법을 알아보았다.
관건은 합쳐지는 데이터의 순서일 것이다.
시간 순서로 데이터를 정렬하기 위해
① 파일 이름을 1, 2, 3....으로 임의로 바꾸거나,
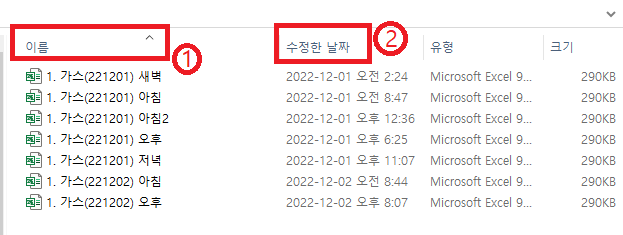
② 파일 생성 순서에 따라 정렬되는 "수정된 날짜" 기준으로 정렬한 후 concat 함수를 실행하면 된다.
이번 글에서는 1개 파일로 만든 1분 데이터를 합쳐놓은 파일에 대해 일부 수정할 내용을 설명할 예정이다.
중복된 분 데이터도 많고 빈칸도 있어서, 실제로 사용자가 분석할 경우 제약이 따를 수 있기 때문이다.
※ 향후 설명할 내용은 아래와 같다.
(1) 영웅문G에서 1분봉 데이터 엑셀로 받기
(2) 데이터 한 파일(엑셀)로 합치기(concat 함수)
(3) 데이터 합친 후 수정사항
2. 사전설명
1) 1분봉 데이터 받아올 때 특징
1분봉을 받아오는 방법은 지난 글에서 설명하였다.
영웅문G에 접속하여 차트조회(화면번호 0603)을 조회한 후, 화면 빈칸에서 우클릭 후 데이터를 받으면 된다.
2) 데이터 합치기
< 그림 1 >의 각각의 1분 데이터를 합친 파일은 아래 "붙임1"과 같다. 600개 데이터 당 7개 파일이므로 합쳐진 엑셀은 4,200줄 정도 될거 같다. ㅠ.ㅠ
붙임1에서 확인가능하겠지만, 4,207줄이다.
이는 각 파일별을 1개 파일로 붙였을 때, 어디에서 붙였는지 구분하기 위해서이다.
이유는? 중복 데이터는 삭제해야 하기 때문이다.
※ 데이터 합치기 링크
3. 데이터 받아온 후 수정사항
1) RSI 14 등 계산이 필요한 일부 데이터는 없음
받아오는 1분봉 데이터는 주의하여 데이터를 분석하여야 한다.
계산이 필요한 일부 데이터는 빈칸이다.
- 최초 1줄~14줄까지 RSI 14 데이터가 없다. 1~14줄까지의 데이터를 기반으로 15줄부터 RSI를 계산하기 때문이다.
- 5분 이평선도 마찬가지로 1~4줄까지 데이터가 없다. 5분 이평선은 1분~5분까지의 평균이다.
2) 마지막줄 데이터의 종가는 현재가이다.
필자가 말하고 싶은 내용이다.
1분봉의 마지막 데이터의 종가는 현재가를 나타낸다.
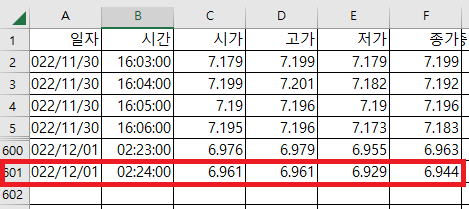
< 그림2 >의 마지막 줄인 601줄을 잘 보자.
600줄 : 시가 : 6.976, 고가 6.979, 저가 6.955, 종가 6.963
601줄 : 시가 : 9.691, 고가 6.961, 저가 6.929, 종가 6.944
영웅문G에서 1분봉 받아오기를 실시할 경우,
601줄의 고가, 저가, 종가는 현재 데이터를 가져온다.
즉, 분봉이 완성되기 전에 601줄의 데이터를 받아오기 때문에, 결론은 최종값이 아니므로, 601줄은 삭제하여야 한다.
3) "구분"의 제목은 바꾸어줄 필요가 있다.
데이터를 1개로 합친 파일의 구분에 한글이 깨졌다.
이유는 잘 모르겠지만, 코딩할 때 encoding = 'utf-8'를 넣었는데 에러가 발생하길래, 해결을 포기했다.
어차피 필자가 쓸 자료인데, 굳이 제목까지 바꾸어서 코딩할 필요는 없어보였다.

4) 중복 데이터 삭제
엑셀에서 중복값 없애기 기능이 있긴 한데, 위의 1번에서처럼 누락된 자료도 있어서, 삭제를 생각처럼 쉽게 할 수 없다.
중복데이터는 수동으로... 지워주는게 마음 편했다.
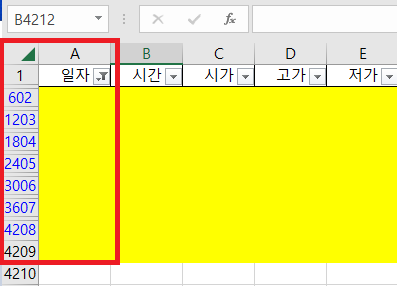
중복데이터는 데이터를 붙인 앞/뒤 파일에서 많이 발생한다.
602줄, 1203줄에서 파일을 각각 붙였다.
필터를 풀고, 노란색 셀을 중심으로 위/아래 데이터의 중복을 확인하자.
데이터를 8~9시간마다 받으니 발생하는 문제이다.
중복되는 부분이 발생하는 것은 필연이다.
처리 방법을 알아보자.
< 그림4-3 >에서 확인가능한듯, ① = ③으로 중복이다.
이때는 ①을 채택한다. 이유? ③ RSI 등의 자료가 누락되어 있다.
완성도 있는 ①을 선택(=③을 삭제)하자.
두번째, ② = ④ 중복이 발생한다.
< 그림2 >에서 설명하였듯이 ②의 마지막 데이터는 완성된 분봉의 데이터가 아니다.
④가 완성된 분봉이므로 ④를 선택(=②를 삭제)한다.
결과적으로 시간순으로 데이터를 배열하려면,
①과 ④을 남겨두고, ②과 ④을 삭제한다.
(중복데이터를 삭제 후 602줄의 빈칸도 삭제)
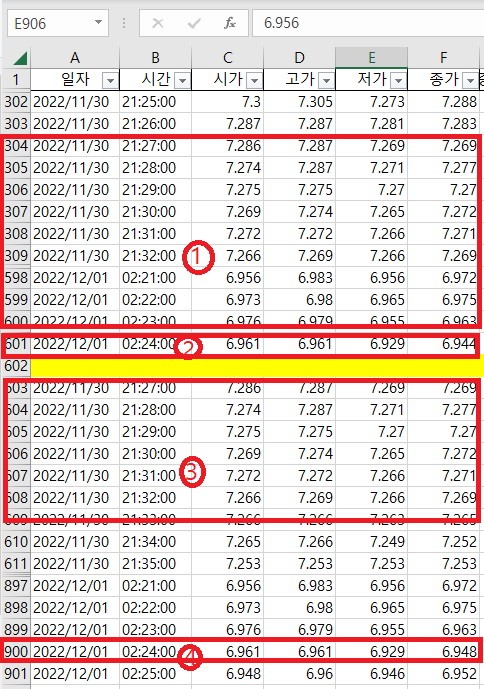
< 그림4-3 >이 조금 복잡한 관계로 다시 설명한다.
< 그림4-4 >처럼 1646줄 ~ 1913줄까지 삭제하면 된다.
(1646줄은 완성되지 않는 분봉이고,
1648~1913은 1635~1913줄과 중복이다)
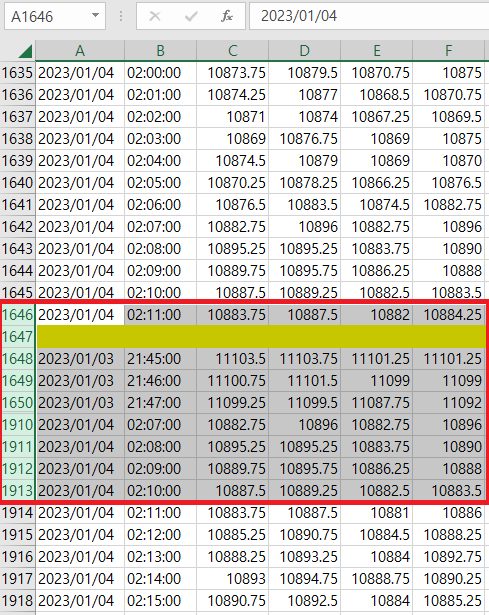
5) 신규 데이터를 붙이는 경우
신규 데이터는 관리하는 통합파일에 수기로 붙이자.
지난 글에서도 확인하였듯이 데이터를 추가해주면...
에러가 발생한다.
4. 마치며
1분봉 데이터 모음을 의미있게 사용하려면, 약간의 작업이 필요한 것은 사실이다.
그래도, 중복데이터를 없애고나서 데이터를 분석하는 것이 조금더 객관적이라고 해야 할 것이다.
글로 써놓고 보니... 상당히 길어졌다.
원래 1분봉 파일의 데이터를 하나씩 하나씩 복사해서, 필자가 관리하는 파일에 붙였는데,
주말 내내 붙여도 2~3시간이 훌쩍 지나갔다.
파일을 붙여 놓는 것은 파이썬에 맡기고, 사용자는 중복데이터 및 유의미한 데이터만 수정하도록 하자.
'2. 해외선물 > 2-3. 해외선물 설명' 카테고리의 다른 글
| (키움증권 해외선물 OpenAPI-W) 1분봉 데이터로 3분봉, 60분봉 만들기 (3) 리스트문과 for문 활용 (중급) (2) | 2023.11.01 |
|---|---|
| (키움증권 해외선물 OpenAPI-W) 1분봉 데이터로 3분봉, 60분봉 만들기 (2) 3분봉 받아보기 (초급) (10) | 2023.10.31 |
| (키움증권 해외선물 OpenAPI-W) 1분봉 데이터로 3분봉, 60분봉 만들기 (1) 개념 이해하기 (2) | 2023.10.30 |
| (키움증권 해외선물) 1분봉 데이터 받기 (4) 키움차트에서 1분봉 받기 (0) | 2023.09.02 |
| (키움증권 해외선물) 1분봉 데이터 받기 (2) 데이터 한 파일(엑셀)로 합치기 (concat 함수) (0) | 2023.01.12 |
| (키움증권 해외선물) 1분봉 데이터 받기 (1) 영웅문G에서 엑셀로 받기 (0) | 2023.01.11 |
| (키움증권 해외선물) 거래 수수료 할인받기 (2) | 2023.01.09 |
| (키움증권 해외선물) 위탁증거금, 유지증거금, 위험도 알아보기 (4) | 2023.01.08 |