목 차
1. 들어가며
2. 사전설명
1) 나스닥 1분봉 차트의 데이터를 받아온다.
2) 1분봉 데이터의 일부 수정이 필요하다.
① 엑셀의 확장자 변경 (xls → xlsx)
② 불필요한 데이터는 삭제한다.
③ 1분봉 엑셀 맨 하단에 위치한 빈칸은 지운다.
3) pandas을 통해 엑셀 데이터 읽어오기
3. 코드설명
4. 전체코드
5. 마치며
1. 들어가며
지난 글에서는 AI 학습을 통해 벽돌깨기 게임의 진행 코드를 알아보았다. 핵심은 AI에 데이터를 학습시키고, 학습된 데이터를 활용으로 벽돌(Brick)을 하나씩 깨는 것이었다. AI가 입력받은 데이터로 벽돌을 깨는게 신기하기도 하고, 패들(paddle)을 통해 공(ball)을 랜덤으로 팅겨내는 등 조금더 욕심을 내고 싶지만, 필자의 최종 목표는 벽돌깨기가 아닌, 해외선물 자동매매에서 수익을 내는 것이기 때문에, 벽돌깨기 코드는 지난 글로 마무리 한다.
이번 글에서는 나스닥 차트 1분봉에서 지지(support), 저항(resistance)을 구하는 방법을 알아본다.
원래는 필자가 가장 좋아하는 볼린저밴드를 통해 스퀴즈(squeeze) 전략을 코드로 구현하려고 했다. 스퀴즈(볼린저밴드 폭이 줄어드는 영역)의 개념은 날짜/시간/요일에 따라 달라지고, 그 기준(횡보를 하는 구간)을 찾으려고 볼린저밴드의 스퀴즈 부분을 계속 관찰하다가, 일단은 지지/저항 먼저 공부하고 볼린저밴드 스퀴즈 전략을 고민하자고 생각했다.
주식/선물 거래를 할 때 차트분석은 필수적이다. 또한, 매수/매도에 따라 거래가 이루어질 때, 봉(candle stick)이 생성된다. 강력하게 지지/저항을 하는 곳에서 롱/숏으로 진입하는 것은 상당히 신중을 기해야 하는 점이다. 바꾸어 말하면, 강력하게 지지/저항한 곳을 이탈했으면, 시장에 변동을 발생하였다는 것을 의미한다.
이렇듯, 차트에서 지지/저항은 투자자에게 진입/청산을 위한 하나의 시그널(signal)을 제공하는 것은 부인할 수 없다.
미리 말씀드리지만, 대단한 개념을 담고있지는 않다. 2가지 당부 말씀을 드리고 글을 진행한다.
- ① 너무 큰 기대는 부담되니, 가볍게 글을 읽어주셨으면 한다. 수많은 1분봉 차트 중 "여기가 지지/저항의 핵심이다"는 개념은 아니니, 큰 기대는 접어두고, 지지/저항에서 필요한 부분만 알아본다는 생각으로 글을 쓰려고 한다.
- ② 나스닥 월물은 같아야 한다. 주식(현물)은 증권사에서 제공하는 데이터는 항상 동일하지만, 선물은 상품의 월물에 따라 지지/저항이 바뀐다(=전월물의 종가가 현월물의 종가와 다른 경우 등). 필자는 '24년 12월 종료되는 MNQZ24 상품으로 분석한다.
우리가 이 글을 통해 최종적으로 구현하고자 하는 결과물은 < 그림 1-1 >의 내용이다. '24년9.30.(월)~10.5(토)까지의 1분봉을 활용한 내용이다. 지지(저가, support)는 나스닥 선물은 19948.0 포인트에서 16번 지지를 했다. 지지한 시간은 10월2일 00:51분, 10일2일 09:05분이었다. 그 바로 밑에 19910은 15번 지지(저가, support)를 했다. 시간은 '24.10.1 23:18분, 10월2일 00:36분 등이었다. 참고로 1분봉 데이터를 활용하였다.

아래 < 그림1-2 >은 '24년 10.2일(수), 09:17분의 1분봉 데이터(저가)이다. 이 글에서 우리가 원하는 "지지/저항"을 정확하게 찾는 것은 절대 불가능 하다. 저항(고가) 및 지지(저가)가 얼마나 많이 나오는지에 대한 내용이다.

동 설명의 파일은 본문 하단에 업로드해 두었다.
2. 사전설명
사전에 1분봉 받아와서, 양식을 수정하는 등 몇 가지 준비사항이 있다. 간단하게 이야기하면, 아래의 111 파일(키움에서 받아온 데이터)을 222 파일(수정한 데이터)로 바꾼다는 의미이다. 아래 데이터는 '24년 9.27(금)~10.5(토) 데이터이다. (222 엑셀 파일을 활용할 것이다)
1) 나스닥 1분봉 차트의 데이터를 받아온다.
예전에 설명한 적이 있다. 링크를 클릭하면 새로운 창이 뜨며, 1분봉 받는 방법이 나온다.
※ 나스닥 1분봉 데이터 받아오는 방법 : https://springcoming.tistory.com/198
2) 1분봉 데이터의 일부 수정이 필요하다.
우리에게 필요한 데이터는 총 7개 데이터(날짜,시간,시가,고가,저가,종가,거래량)이다. 필자의 코드에서 필요한 것은 4개(날짜,시간,고가,저가)이지만, 일단 7개 데이터로 엑셀을 만들자.
① 엑셀의 확장자 변경 (xls → xlsx)
키움증권에서 1분봉 차트를 최초로 받아올 때, 확장자는 xls이다. 이것을 "다른 이름으로 저장하기 " 에서 xlsx로 변경한다. 이유는? 이유는 확장자 xls인 파일을 pandas 라이브러리로 읽어오면, 글자가 깨지는 문제가 종종 발생한다.
② 불필요한 데이터는 삭제한다.
필자는 7개 데이터(날짜, 시간, OHLCV)만 활용할 예정이다. 5분봉, 10분봉, 볼린저 상단/하단 등은 지운다. 아래 < 접은글 >의 < 그림 1-3 >은 데이터 삭제전의 로데이터이며, < 그림 1-4 >은 필요한 데이터만 남긴 예시이다.
분석하고 싶은 날짜/시간만 남기고, 이전의 날짜/시간은 삭제하자. 필자의 경우, '24년 9.30(월)~10.5(토)까지 분석하고 싶었는데, 데이터를 9.27부터 가져왔다. 필자에게 불필요한 9.27(금)~9.28(토) 데이터는 삭제하였다.


③ 1분봉 엑셀 맨 하단에 위치한 빈칸은 지운다.
날짜/시간의 오름차순으로 키움증권에서 데이터를 받아오면, 엑셀의 맨 하단에 "빈칸" 데이터 26줄이 생긴다. < 접은글 >의 < 그림 1-5 >에서는 노란색 부분이다. 이 부분도 삭제하자. 이유는? pandas를 통해 데이터를 불러올 때, 엑셀의 빈칸을 "데이터"로 인식한다. 필자는 불러운 데이터를 곱하거나 나눌 것(사칙연산)인데, "빈칸" 데이터에 사칙연산을 적용하면 에러가 난다. (필자의 코드에서는 52줄에서 에러가 발생한다)
에러 내용은 아래와 같다. 불필요한 부분은 < 그림 1-5 > 및 < 그림 1-6 >를 참고하여 삭제하자.
ValueError: invalid literal for int() with base 10: '


3) pandas을 통해 엑셀 데이터 읽어오기
파이썬에서 엑셀 데이터를 읽어오는 여러방법 중 필자는 2가지(openpyxl, pandas)를 사용한다. 필자가 사용해본 결과 pandas 라이브러리가 엑셀을 훨씬 빨리 읽어온다. 앞으로 엑셀 데이터를 사용하여 분석할 필요가 있을 때는 pandas를 사용할 것 같다.
아래 < 접은글 >의 < 그림 1-7 >는 openpyxl로 엑셀 데이터를 읽어오는 코드는 for문을 이용하였기 때문에 상당한 시간이 걸린다. 이에비해, < 그림 1-8 >은 pandas를 활용하여 읽어오니, 데이터를 한번에 쓱~~~ 받아온다.
실제 필자가 시행착오를 겪어본 결과, 엑셀의 15,832개 데이터를 파이썬으로 읽어올 때 걸리는 시간에 엄청난 차이가 있었다.
- openpyxl 라이브러리 사용 : 15,832줄의 7개 데이터(날짜,시간, OHLCV) 받아오는 시간 → 1,045초 (약 20분)
- pandas 라이브러리 사용 : 15,832줄의 7개 데이터(날짜,시간, OHLCV) 받아오는 시간 → 120초 (거의 2분)
import openpyxl
class btl_minute_test():
def __init__(self):
dir = r'C:\Users\User\Desktop\222.xlsx' # 경로 설정
wb = openpyxl.load_workbook(dir) # 엑셀파일 열기
ws = wb.active
num_under_1 = ws['c']
self.num_under_2 = list(num_under_1) # '구분' 포함
num_right_1 = ws['2']
self.num_right_2 = list(num_right_1)
self.ccc = []
self.ddd = []
for i in range(len(self.num_right_2)): # 날짜별/시간별/시가별 등 각각 출력
for j in range(2, len(self.num_under_2) + 1):
num_under_3 = ws[str(j)]
num_under_4 = list(num_under_3)
if num_under_4[i].value != None:
self.ccc.append(num_under_4[i].value)
self.ddd.append(self.ccc)
self.ccc = []그림 1-7. openpyxl를 사용하여 엑셀 데이터를 받아온 경우
import pandas as pd
class btl_minute_test():
def __init__(self):
dir = r'C:\Users\User\Desktop\222.xlsx' # 경로 설정
aaa = pd.read_excel(dir, engine = "openpyxl")
self.data_1 = []
self.time_1 = []
self.open_1 = []
self.high_1 = []
self.low_1 = []
self.close_1 = []
self.volume_1 = []
aaa_list = aaa.values.tolist() # 데이터프레임(Dataframe)을 리스트 태형으로 변경한다그림 1-8. pandas를 사용하여 엑셀 데이터를 받아오는 경우
3. 코드설명
필자가 말하는 지지/저항은 저가/고가가 2개 이상 반복될 때 지지/저항값으로 정의하고자 한다. 물론 끝없이 하락하다가, 상승을 할 때, 그때를 지지값으로 볼 수 있다. 하지만, 그 점(지지값)을 구하는게 만만하지는 않다.
일단 여기서는 저가/고가가 2번 이상 반복되는 저가/고가를 찾을 것이다.

1줄~4줄 : 해당 코드에서 활용하는 라이브러리이다.
1줄~2줄 : sys 모듈 및 PyQt5.QtWidgets는 코딩이 종료되지 않도록 할 때 사용된다. (163줄에서 활용)
3줄 : os모듈은 텍스트 위치의 경로를 확인한다. (8줄, 123줄~151줄에서 활용)
4줄 : pandas 모듈은 엑셀 데이터를 데이터 프레임 형태로 불러올 때 쓰인다. (10줄)
8줄 : 엑셀의 경로를 설정한다. (확장자가 xlsx임을 기억하자)
9줄 : 데이터프레임 형태(가로x세로)로 받아온 엑셀 데이터를 aaa 변수에 담는다
10줄 : 데이터프레임(DataFrame) 형태를 리스트 태형으로 바꾼다.
14줄~20줄 : 날짜,시간, OHLCV의 총 7가지를 담을 리스트를 각각 선언한다.
22줄~20줄 : 12줄에서 리스트 태형으로 바꾼 데이터를 "날짜, 시간, OHLCV"의 리스트에 각각 담는다.
31줄~33줄 : 고가/시가를 담을 리스트를 선언한다.

35줄 : 47줄의 함수(high_low_list)를 실행한다. (날짜, 분, 고가, 저가를 리스트에 담는다)
37줄~45줄 : 지지 및 저항을 구하기 위해 리스트를 선언한다.
39줄,44줄 : 90줄~91줄에서 중복이 많은 지지/저항을 내림차순으로 정렬하기 위해 딕셔너리 형태로 선언한다.
47줄~49줄 : for문과 zip함수를 활용하여 "날짜, 시간, 고가, 저가"를 한 쌍으로 self.high_low_list_first에 담는다. (95줄, 109줄에서 활용된다)
51줄~53줄 : for문과 zip함수를 이용하여 "고가, 저가"를 self.high_low_list_second에 각각 담는다. 여기서 2가지를 알아야 한다.
첫번째는 데이터가 담기는 방식을 확인하자.(57줄에서 활용)
self.high_low_list_second = [고가1, 저가1, 고가2, 저가2, 고가3, 저가3.....]
고가의 위치는 위의 리스트(second)에서 고가1은 리스트[0], 고가2는 리스트[2], 고가3은 리스트[4] 등의 짝수 위치에 존재한다.
두번째는 100을 곱한 이유는 부정소수점의 문제를 해결하기 위함이다. (59줄, 62줄에서 활용)
부정소수점 문제 회피하기는 예전에 한번 설명하였으므로 링크를 참고하자.
(https://springcoming.tistory.com/146)
나스닥의 틱단위는 0.25이다. 부정소수점 문제는 "실수 - 실수"를 계산하면 소수점이 10개 이상 나온다는 것이다.
a = 1.25
b = 1.24
print(a-b)
# 결과값은 0.010000000000000009
이렇듯 "실수-실수"를 계산했을 때 발생하는 부정소수점 문제를 회피하기 위해, 위의 a(1.25)에 100을 곱하고, b(1.24)에 100을 곱하여 뺀 값은 1이다. 이것(결과값 1)에 다시 100으로 나누면 0.01이 된다. 왜 이렇게 번거롭게 해야 하는가? 부정소수점 문제를 회피하기 위함이다. 즉, 1.25-1.24 = 0.01 값을 얻으려면, 이렇게 번거로울 수 밖에 없다. ^^;
그런데 코드를 다 짜고 생각해보니, 소개할 코드에서는 사칙연산을 사용하지 않을 것이기 때문에.... 굳이 100을 곱할 필요는 없어 보인다. ㅠㅠ
56줄~63줄 : 고가~저가 사이의 가격을 나스닥 단위인 0.25단위로 풀어써 주는 코드이다. 결과론적으로 이번글에서는 굳이 숫자를 풀어서 쓸 필요는 없었을 거 같다. 어차피 나에게 필요한 건 고가/저가 중 많이 겹치는 숫자에 따라, 지지/저항을 구하려고 했기 때문이다. 원래는 58줄에서 양봉, 61줄에서 음봉일 때, 고가~저가 사이의 숫자를 풀어쓰려고 했다. 근데 현재 적혀있는 코드는 고가 > 저가... 이렇게 숫자가 풀어쓰는 코드를 작성하였다. ㅠㅠ 대세에는 지장 없으므로, 위 코드를 특별히 수정하지는 않았다.
※ 숫자를 풀어쓴다는 의미는? 나스탁 틱단위 0.25이고, 고가 3.75, 저가 2.75이면... 그 사이에 있는 숫자는? [3.75, 3.5, 3.25, 3.0, 2.75] 이렇게 풀어쓰고 싶었다.
57줄~63줄 : 51줄~53줄에서 고가/저가를 순서대로 담았다. [고가1, 저가1, 고가2, 저가2, 고가3, 저가3, ...]형태의 리스트에서 자릿수가 짝수이면 위 "고가"를 말한다.
65줄~78줄 : 여기도 아쉬운건, [고가1, 저가1, 고가2, 저가2...]로 기재되어 있다. 고가는 저가보다 항상 크거나 같으므로, 66줄~74줄만 쓰인다. 뭐, 그래도 코드는 돌아가니... 이 글에서는 특별히 수정하지 않는다.
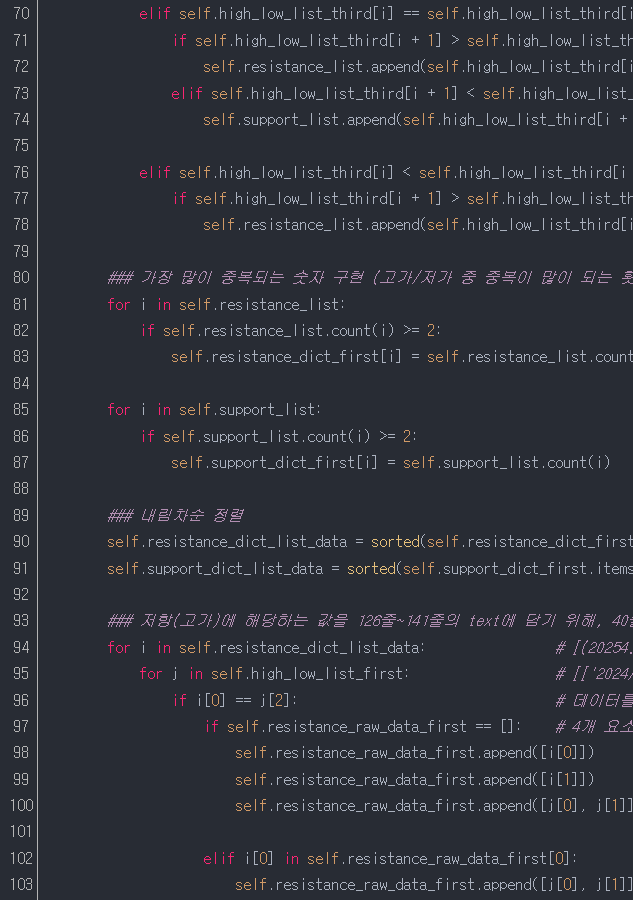
81줄~87줄 : 고가/저가 중 중복이 많은 숫자를 찾기 위한 숫자이다.
82줄 : 고가 중 중복이 2개 이상인 저항을 83줄의 리스트에 담는다.
86줄 : 저가 중 중복이 2개 이상인 지지를 87줄의 리스트에 담는다.
90줄~91줄 : 2개 이상인 요소들의 모음인 지지/저항 리스트 태형을 딕셔너리(dict)를 이용하여 내림차 순으로 정렬한다.
94줄~120줄 : 저항(resistance) 및 지지(support)에 해당하는 값을 text 값에 담기 위해 리스트 태형으로 바꾼다.

122줄~140줄 : 저항(고가 2개 이상)을 텍스트에 담는다.

143줄~160줄 : 지지(2개 이상의 저가)을 텍스트에 담는다.
4. 전체 코드
전체 코드는 아래의 < 접은글 >을 참고하면 된다.
import sys
from PyQt5.QtWidgets import *
import os
import pandas as pd
class btl_minute_test():
def __init__(self):
dir = r'C:\Users\User\Desktop\222.xlsx' # 경로 설정
aaa = pd.read_excel(dir, engine = "openpyxl")
aaa_list = aaa.values.tolist() # 데이터프레임(Dataframe)을 리스트 태형으로 변경한다
self.data_1 = []
self.time_1 = []
self.open_1 = []
self.high_1 = []
self.low_1 = []
self.close_1 = []
self.volume_1 = []
for i in aaa_list:
self.data_1.append(i[0])
self.time_1.append(i[1])
self.open_1.append(i[2])
self.high_1.append(i[3])
self.low_1.append(i[4])
self.close_1.append(i[5])
self.volume_1.append(i[6])
self.high_low_list_first = []
self.high_low_list_second = []
self.high_low_list_third = []
self.high_low_list() # 47줄 실행 (날짜, 시간, 고가, 저가를 12줄~18줄의 리스트에 담는다)
self.resistance_list = []
self.resistance_list_first = []
self.resistance_dict_first = {}
self.resistance_raw_data_first = []
self.support_list = []
self.support_list_first = []
self.support_dict_first = {}
self.support_raw_data_first = []
def high_low_list(self):
for i, j, k, l in zip(self.data_1, self.time_1, self.high_1, self.low_1): ### 날짜 시간 표기
self.high_low_list_first.append([i, j, k, l])
for i, j in zip(self.high_1, self.low_1):
self.high_low_list_second.append(int(i * 100)) # 1분봉 데이터(엑셀)의 빈칸을 없애주지 않으면, 여기서 에러 발생한다.(ValueError: invalid literal for int() with base 10: ')
self.high_low_list_second.append(int(j * 100))
def resistance_support_making(self):
for i in range(len(self.high_low_list_second)):
if i % 2 == 0:
if self.high_low_list_second[i] <= self.high_low_list_second[i + 1]: # 양봉
for j in range(self.high_low_list_second[i], self.high_low_list_second[i + 1] + 25, 25):
self.high_low_list_third.append(j / 100)
elif self.high_low_list_second[i] > self.high_low_list_second[i + 1]: # 음봉
for j in range(self.high_low_list_second[i], self.high_low_list_second[i + 1] - 25, -25):
self.high_low_list_third.append(j / 100)
for i in range(len(self.high_low_list_third) - 2):
if self.high_low_list_third[i] > self.high_low_list_third[i + 1]: # 하락 중
if self.high_low_list_third[i + 1] < self.high_low_list_third[i + 2]:
self.support_list.append(self.high_low_list_third[i + 1])
elif self.high_low_list_third[i] == self.high_low_list_third[i + 1]:
if self.high_low_list_third[i + 1] > self.high_low_list_third[i + 2]:
self.resistance_list.append(self.high_low_list_third[i + 1])
elif self.high_low_list_third[i + 1] < self.high_low_list_third[i + 2]:
self.support_list.append(self.high_low_list_third[i + 1])
elif self.high_low_list_third[i] < self.high_low_list_third[i + 1]: # 상승 중
if self.high_low_list_third[i + 1] > self.high_low_list_third[i + 2]:
self.resistance_list.append(self.high_low_list_third[i + 1])
### 가장 많이 중복되는 숫자 구현 (고가/저가 중 중복이 많이 되는 횟수)
for i in self.resistance_list:
if self.resistance_list.count(i) >= 2:
self.resistance_dict_first[i] = self.resistance_list.count(i) # 딕셔너리 형태로 만들어준다. (90줄에서 가장 많이 중복되는 숫자를 내림차순으로 정렬하기 위함)
for i in self.support_list:
if self.support_list.count(i) >= 2:
self.support_dict_first[i] = self.support_list.count(i)
### 내림차순 정렬
self.resistance_dict_list_data = sorted(self.resistance_dict_first.items(), key=lambda x: x[1], reverse=True) # 내림차순 : 딕셔너리 태형이 리스트로 바뀌고, 딕셔너리는 튜플 형태로 바뀐다.
self.support_dict_list_data = sorted(self.support_dict_first.items(), key=lambda x: x[1], reverse=True)
### 저항(고가)에 해당하는 값을 126줄~141줄의 text에 담기 위해, 40줄에서 선언한 리스트에 담는다.
for i in self.resistance_dict_list_data: # [(20254.5, 3), (20259.75, 2), (20234.0, 2), (20240.5, 2)]
for j in self.high_low_list_first: # [['2024/09/28', '03:00:00', 20288.5, 20277.75], ['2024/09/28', '03:01:00', 20293.5, 20278.5], ... ]
if i[0] == j[2]: # 데이터를 어떤 태형으로 담을지 # [[20254.5], [3], ['2024/09/28', '03:00:00'],['2024/09/28', '03:23:00'],,,]]
if self.resistance_raw_data_first == []: # 4개 요소를 넣기 위해 리스트 태형을 만들어 준다 (TypeError: list.append() takes exactly one argument (4 given))
self.resistance_raw_data_first.append([i[0]])
self.resistance_raw_data_first.append([i[1]])
self.resistance_raw_data_first.append([j[0], j[1]])
elif i[0] in self.resistance_raw_data_first[0]:
self.resistance_raw_data_first.append([j[0], j[1]])
btl.resist_support_do_write()
self.resistance_raw_data_first = []
for i in self.support_dict_list_data:
for j in self.high_low_list_first: # 리스트에 저장된 데이터는 [['2024/09/28', '03:00:00', 20288.5, 20277.75]]이다. (여기서 고가는 j[2]이고, 저가는 j[3]이다)
if i[0] == j[3]: # 중복많은 값 및 최저값(j[3])이 동일하게 설정하여야 함 # 96줄은 고가j[2]이며, 110줄은 저가j[3]임에 유의하자
if self.support_raw_data_first == []:
self.support_raw_data_first.append([i[0]])
self.support_raw_data_first.append([i[1]])
self.support_raw_data_first.append([j[0], j[1]])
# print(self.support_raw_data_first)
elif i[0] in self.support_raw_data_first[0]:
self.support_raw_data_first.append([j[0], j[1]])
btl.resist_support_do_write()
self.support_raw_data_first = []
def resist_support_do_write(self):
dir_resistance = './resistance_list.txt' # 상대경로의 파일 유무
dir_support = './support_list.txt'
if self.resistance_raw_data_first:
if os.path.isfile(dir_resistance):
f = open('resistance_list.txt', 'r')
self.resistance_raw_file = f.readlines()
f.close()
if os.path.isfile(dir_resistance):
if self.resistance_raw_data_first not in self.resistance_raw_file:
f = open('resistance_list.txt', 'a')
f.write(str(self.resistance_raw_data_first) + '\n') # 문자형으로 바꾼 이유 : 리스트 태형은 텍스트에 기록할 수 없음(TypeError: write() argument must be str, not list)
f.close()
else:
f = open('resistance_list.txt', 'w') # 쓰기 # 경로 없이 파일이름만 적으면, 실행 파일과 동일한 경로에 있는 텍스트 파일이 열린다.
f.write(str(self.resistance_raw_data_first) + '\n')
f.close()
elif self.support_raw_data_first:
if os.path.isfile(dir_support):
f = open('support_list.txt', 'r')
self.support_raw_file = f.readlines()
f.close()
if os.path.isfile(dir_support):
if self.support_raw_data_first not in self.support_raw_file:
f = open('support_list.txt', 'a') # 추가
f.write(str(self.support_raw_data_first) + '\n') # 문자형으로 바꾼 이유는 리스트 태형은 텍스트에 기록할 수 없음(TypeError: write() argument must be str, not list)
f.close()
print("완료되었습니다.")
else:
f = open('support_list.txt', 'w') # 쓰기
f.write(str(self.support_raw_data_first) + '\n')
f.close()
if __name__ == "__main__":
app = QApplication(sys.argv)
btl = btl_minute_test()
btl.resistance_support_making()
app.exec_()
5. 마치며
이 글은 1분봉의 고가/저가는 각각 저항/지지의 역할을 한다는 가정하에 쓰였다. 투자자들이 생각하는 계속 하락후 반등하는 자리의 "저가"는 나타내는 것은 당분간은 어려울 것으로 생각된다. 그래도 이런 시도들이 언젠가는 지지/저항을 찾는 시작이라고 생각한다.
다음 글에서는 이렇게 만들어놓은 지지/저항 데이터(text)를 업데이트 하는 방법을 알아보자.
'2. 해외선물 > 2-2. 해외선물 알고리즘 연구' 카테고리의 다른 글
| (해외선물 자동매매) 차트 지지/저항 구하기 (5) 나스타 차트 지지, 저항 업데이트 하기 (3) | 2024.10.14 |
|---|---|
| (해외선물 자동매매) 차트 지지/저항 구하기 (3) AI를 활용한 벽돌깨기 게임 (1) | 2024.10.06 |
| (해외선물 자동매매) 차트 지지/저항 구하기 (2) 벽돌깨기 게임 학습하기 (0) | 2024.10.05 |
| (해외선물 자동매매) 차트 지지/저항 구하기 (1) 벽돌깨기 게임 구현하기(BricksBreak) (1) | 2024.10.04 |
| (해외선물 자동매매 알고리즘) (2) 역전파(backpropagation) 알고리즘 구현하기 (6) | 2024.02.08 |
| (해외선물 자동매매 알고리즘) (1) 역전파(backpropagation) 구현을 위한 numpy 이해하기 (2) | 2024.02.07 |
| (해외선물 자동매매 알고리즘) (2) 선형회귀분석 설명 (경사하강법) (2) | 2024.01.30 |
| (해외선물 자동매매 알고리즘) (1) 선형회귀분석 설명 (개념설명) (2) | 2024.01.29 |