목 차
1. 들어가며
2. 사전설명
1) 지지/저항값은 리스트 태형으로 저장한다.
2) 줄바꾸기(\n), 문자열 제거(strip) 및 리스트 태형으로 변경(eval)
① 줄바꾸기(\n)
② 문자열 및 공백제거(strip)
③ 리스트 태형으로 변경(eval)
3. 코드설명
4. 전체코드
5. 마치며
1. 들어가며
지난글에서는 나스닥 차트의 지지/저항 데이터를 텍스트에 기록하는 방법을 알아보았다. 필자가 말하는 지지/저항은 고점/저점이 2번 이상 반복되는 경우를 말한다. 물론 어느 지점이 정확히 지지/저항인지는 아무도 모른다. 다만, 2번 이상 지지/저항을 했다는 것은 앞으로도 그 값은 의미(지지/저항)가 있다고 생각한다. 지지/저항에 대해 조금더 고민해 보아야 할 것 같다.
이번글에서는 지지/저항 값을 업데이트하는 방법을 알아보자. 정확히는 텍스트(text)의 데이터를 수정하는 방법을 설명할 것이다. 지난글에서 만들었던 텍스트의 내용(지지/저항 값)은 문자형(str)의 리스트이다. 이 문자형을 어떻게 읽어와서, 업데이트 후 다시 텍스트에 보낼지가 핵심이다.
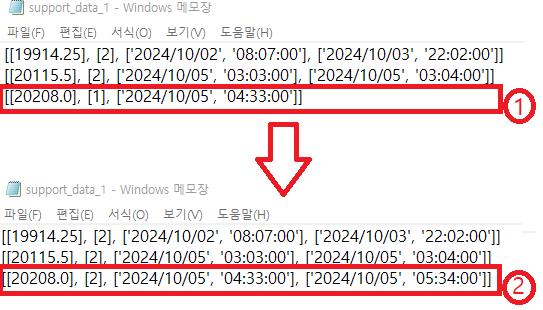
우리가 이 글에서 알아보고자 하는 것은 아래 < 그림1 >의 지지(20208.0)를 나타낸다. 지지값(20208.0)이 한번더 지지(저점)된 값을 중복 횟수, 시간 등을 업데이트 하고자 한다.
실행파일은 본문의 맨 하단에 있다.(py 파일)
2. 사전설명
1) 지지/저항값은 리스트 태형으로 저장한다.
데이터 저장 방법은 크게 튜플형, 딕셔너리형, 리스트형의 3가지가 있다. 필자는 리스트 태형이 익숙하다. 그래서 리스트 태형을 여기에서 활용한다. 2중 리스트 태형을 이용한다. < 그림1 >에서처럼, 리스트[리스트1, 리스트2, 리스트3...]으로 이루어진다.
< 그림1 >의 ①은 지지값(20208.0)이 한번 지지(저점, support)된 경우이다. ①은 20208에서 1번 지지되었고, 2024년 10월 5일 04:33분 저점(지지)을 기록하였다. ②는 2024년10월 5일 05:34분 한번 더 지지되었다.
2) 줄바꾸기(\n), 문자열 제거(strip) 및 리스트 태형으로 변경(eval)
우리는 리스트 태형의 데이터를 텍스트에 저장할 것(① 줄바꿈 \n을 활용)한다. 그다음 "텍스트에 저장된 리스트 데이터의 문자형"을 불러올 때는 줄바꿈(\n)을 제거(② strip)한다. 마지막으로 텍스트에서 불러온 "리스트 모형이나, 실제는 문자형인 데이터"를 리스트 태형으로 바꿀 것(③ eval)이다.
① 줄바꾸기(\n)
줄바꾸기는 \n이다. 줄바꾸기를 하지 않으면, < 그림1 >의 리스트 데이터가 한줄을 붙어서 나온다. 한줄에 한 데이터만 담으려면 \n을 넣으면 된다.
aaa = 'abcde\n'
print(aaa)
# abcde
#
② 문자열 및 공백제거(strip)
문자열 및 공백제거는 strip 명령어를 사용한다. 텍스트에 1번 데이터를 넣고, 그 다음줄에 2번 데이터를 넣을 때는 줄바꿈(\n)을 사용했다. 텍스트에 저장된 데이터1, 데이터2를 파이썬으로 불러오면 아래와 같이 데이터가 출력된다.(=데이터 별로 한줄이 삽입(\n)되었다)
[[19914.25], [2], ['2024/10/02', '08:07:00'], ['2024/10/03', '22:02:00']]
[[20115.5], [2], ['2024/10/05', '03:03:00'], ['2024/10/05', '03:04:00']]
[[20208.0], [1], ['2024/10/05', '04:33:00']]
정리를 하면, 데이터를 텍스트에 저장할 때는 줄바꿈(\n)을 넣어주고, "텍스트에 저장된 데이터"를 파이썬에 불러와서 활용할 때는 줄바꿈(\n)을 제거(strip)한다.
aaa = 'abcde\n'
bbb = aaa.strip('\n')
print(bbb)
# abcde
③ 리스트 태형으로 변경(eval)
"리스트 태형 "의 텍스트 내용을 파이썬에 불러오면, 태형은 문자형이다.
[[19914.25], [2], ['2024/10/02', '08:07:00'], ['2024/10/03', '22:02:00']]
<class 'str'>
[[20115.5], [2], ['2024/10/05', '03:03:00'], ['2024/10/05', '03:04:00']]
<class 'str'>
[[20208.0], [1], ['2024/10/05', '04:33:00']]
<class 'str'>
문자형을 리스트 태형으로 바꾸어 주는 것은 eval 함수이다.
[[19914.25], [2], ['2024/10/02', '08:07:00'], ['2024/10/03', '22:02:00']]
<class 'list'>
[[20115.5], [2], ['2024/10/05', '03:03:00'], ['2024/10/05', '03:04:00']]
<class 'list'>
[[20208.0], [1], ['2024/10/05', '04:33:00']]
<class 'list'>
3. 코드설명
아래 코드들은 우리가 이미 만들어놓은 지지/저항의 텍스트 값을 업데이트 한다는 것(will_update_data)이다. 텍스트 값을 불러와서, 업데이트 하고, 다시 텍스트에 보내는 내용을 설명한다.

1줄 : 2줄에서 텍스트 파일의 경로를 설정하기 위해 os 라이브러리를 활용한다.
2줄 : 지지/저항이 저장된 텍스트 파일의 경로를 설정한다.
5줄 : 이미 저장된 텍스트 파일에 업데이트할 데이터(will_update_data)이다.
7줄~9줄 : 텍스트 파일에 저장된 지지/저항 값을 불러와서, read_raw_text에 저장한다.
11줄 : 업데이트할 데이터를 저장할 리스트를 선언한다. (34줄, 44줄, 49줄에서 활용한다)
13줄 : 2줄에서 선언한 경로에 파일이 있으면,
14줄 : 8줄에서 저장한 내용(read_raw_text)를 for 문을 활용하여 하나씩 추출한다.
15줄~16줄 : 불러온 데이터(data)에서 줄바꿈(\n)을 제거(strip)하고, 불러온 데이터(문자형)를 리스트 태형으로 바꾼다.(eval)
18줄 : 16줄에서 리스트 태형으로 바꾼 내용의 [[19914.25], [2], ['2024/10/02', '08:07:00'], ['2024/10/03', '22:02:00']]에서 2번 이후의 내용(['2024/10/02', '08:07:00'], ['2024/10/03', '22:02:00'])이다.
19줄 : 2줄의 업데이트할 데이터의 첫번째 값(20208.0)이 16줄의 데이터 첫번째 값(20208.0)과 같다면, (=텍스트에 지지값을 찾음)
21줄 : 텍스트에 저장될 두번째(1) 값을 업데이트 한다. 두번째 값은 중복된 숫자이다. 기존에 1번 나온 값(20208)이, 한번더 나오면 2로 바꾼다. (replace 명령어 사용)
22줄~23줄 : 리스트 태형으로 바꾸고(eval 명령어), 21줄에서 업데이터된 중복값(숫자 2)을 데이터에 저장(after_update_data)한다.
25줄 : 14줄의 for문에서 추출한 텍스트 데이터의 첫번째(지지값)이, 23줄에서 업데이트한 값(지지값)과 같은 경우,
26줄~27줄 : 8줄의 텍스트에 저장된 전체 내용 갯수(여기서는 그림 1-1의 5개)에서 추출한다.
* 5개가 되는 이유 : ['2024/10/02', '08:07:00'], ['2024/10/03', '22:02:00'],
['2024/10/05', '03:03:00'], ['2024/10/05', '03:04:00'],
['2024/10/05', '04:33:00']

29줄 : 23줄에서 수정한 데이터를 문자형으로 바꾸고(str)고 줄바꿈(\n)을 추가한다. 이렇게 데이터를 만드는 이유는 텍스트에 데이터를 보낼 때, 리스트 태형이 아닌, 문자형으로 바꾸어 주어야 한다. 그리고 텍스트 가독성을 위해 줄바꿈(\n)을 추가해준다.
문자형으로 바꾸지 않으면, 아래와 같은 에러가 발생한다. 아래와 같은 에러를 방지하기 위해 리스트 태형을 문자형(str)으로 바꾸어준다.
read_raw_text[k] = after_update_data + "\n"
TypeError: can only concatenate list (not "str") to list
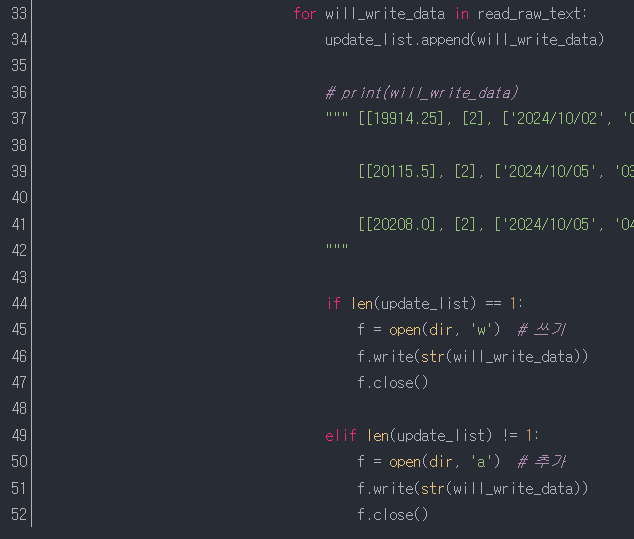
33줄~52줄 : 여기서부터는 업데이트 한 내용(29줄)을 텍스트에 담는 내용이다.
33줄 : 29줄에서 업데이트한 내용(read_raw_text)에서 하나씩 추출한다.
34줄 : 추출한 내용을 11줄에서 선언한 리스트에 담는다.
44줄~52줄 : 업데이트한 리스트를 텍스트에 담는다.
4. 전체코드
전체코드는 52줄이다. 기존 데이터의 경로, 데이터의 형태(리스트형, 문자형)에 주의하자.
import os
dir = r'C:\Users\User\Desktop\support_data_1.txt' # 경로 설정
will_update_data = [[20208.0], [1], ['2024/10/05', '05:34:00']] # 로데이터(text)에 업데이트할 요소
f = open(dir, 'r') # 읽기
read_raw_text = f.readlines()
f.close()
update_list = []
if os.path.isfile(dir):
for data in read_raw_text:
raw_data_strip_list = data.strip("\n")
raw_data_strip_list = eval(raw_data_strip_list)
for j in raw_data_strip_list[2:]:
if will_update_data[0] == raw_data_strip_list[0]:
if will_update_data[2] not in raw_data_strip_list[2:]:
after_update_data = data.replace(str(raw_data_strip_list[1]), str([raw_data_strip_list[1][0] + 1]))
after_update_data = eval(after_update_data)
after_update_data.append(will_update_data[2])
if eval(data)[0] == after_update_data[0]:
for k in range(len(read_raw_text)):
if eval(read_raw_text[k])[0] == after_update_data[0]:
read_raw_text[k] = str(after_update_data) + "\n"
# print(read_raw_text) # ["[[19914.25], [2], ['2024/10/02', '08:07:00'], ['2024/10/03', '22:02:00']]\n", "[[20115.5], [2], ['2024/10/05', '03:03:00'], ['2024/10/05', '03:04:00']]\n", "[[20208.0], [2], ['2024/10/05', '04:33:00'], ['2024/10/05', '05:34:00']]\n"]
# print(type(read_raw_text)) # <class 'list'>
for will_write_data in read_raw_text:
update_list.append(will_write_data)
# print(will_write_data)
""" [[19914.25], [2], ['2024/10/02', '08:07:00'], ['2024/10/03', '22:02:00']]
[[20115.5], [2], ['2024/10/05', '03:03:00'], ['2024/10/05', '03:04:00']]
[[20208.0], [2], ['2024/10/05', '04:33:00'], ['2024/10/05', '05:34:00']]
"""
if len(update_list) == 1:
f = open(dir, 'w') # 쓰기
f.write(str(will_write_data))
f.close()
elif len(update_list) != 1:
f = open(dir, 'a') # 추가
f.write(str(will_write_data))
f.close()
5. 마치며
텍스트 데이터를 업데이트 하는 방법을 알아보았다. 텍스트 자료를 불러오고, 수정하고, 다시 텍스트로 보내는 방법이 생각보다 어려웠다. 그러면서 데이터 태형이 어떻게 바뀌는지 시행착오를 계속 겪다보니, 어느 정도 데이터 태형에 익숙해진 것 같다.
지금은 이렇게 업데이트를 하지만, 사실 이전글에서처럼 데이터를 새롭게 만드는게 더 편할 거 같다. 필자가 당초 생각한건, 자동매매를 하면서 당일의 1분봉의 지지/저항을 업데이트 하면서, 진입/청산을 생각해 보자고 생각했는데... 매매 중 얼마나 이 데이터(지지/저항)를 활용할 수 있을지 약간의 의문이 든다. ^^;
아래는 위에서 설명한 파일이다. support_data_1의 텍스트 내용을 업데이트 한다.
또한, text_test_4(update).py 파일은 위에서 설명한 파일이다.
다음 글에서는 마지막으로 피보나치 되돌림을 활용하여 패턴을 만드는 방법을 알아보자.
'2. 해외선물 > 2-2. 해외선물 알고리즘 연구' 카테고리의 다른 글
| (해외선물 자동매매) 차트 지지/저항 구하기 (4) 나스타 차트 지지, 저항 구하기 (3) | 2024.10.07 |
|---|---|
| (해외선물 자동매매) 차트 지지/저항 구하기 (3) AI를 활용한 벽돌깨기 게임 (1) | 2024.10.06 |
| (해외선물 자동매매) 차트 지지/저항 구하기 (2) 벽돌깨기 게임 학습하기 (0) | 2024.10.05 |
| (해외선물 자동매매) 차트 지지/저항 구하기 (1) 벽돌깨기 게임 구현하기(BricksBreak) (1) | 2024.10.04 |
| (해외선물 자동매매 알고리즘) (2) 역전파(backpropagation) 알고리즘 구현하기 (6) | 2024.02.08 |
| (해외선물 자동매매 알고리즘) (1) 역전파(backpropagation) 구현을 위한 numpy 이해하기 (2) | 2024.02.07 |
| (해외선물 자동매매 알고리즘) (2) 선형회귀분석 설명 (경사하강법) (2) | 2024.01.30 |
| (해외선물 자동매매 알고리즘) (1) 선형회귀분석 설명 (개념설명) (2) | 2024.01.29 |